前言
不是每一道题都有思路解释,没有思路解释的题目说明只是简单的模拟,不需要多余的讲解。
4001 HTML解析
题目描述
如果你在一台没有安装Netscape浏览器的Macintosh机器上,试着阅读一个html文档,那是件非常困难的事情。 你的任务是要编程实现一个小的html浏览器。要求显示输入文件的内容,你需要知道html的标签: 表示换行,<hr>表示水平线,另外还有制表符,空格和换行符。每行不超过80个字符。
输入
输入包括一个你要显示的内容文本。这个文本包括一些单词和HTML标签,它们由一个或多个空格、制表符或换行符分割开的。 一个单词是指由0个或多个字母、数字和标点符号组成的一个序列。例如,abc,123 是一个词,但是abc, 123是两个词,即abc, and 123(即以空格作为单词的分隔符)。一个词不会超过81个字符,而且不会包含任何<或>符号。所有的HTML标签不是br就是hr。
输出
你应该按照如下规则来显示输入的文本: (1) 如果你读入的词,结果行没有超过80个字符,那么就显示它,否则换行显示。 (2) 如果你读入 标签,则开始一个新行。 (3) 如果你读入<hr>标签,则要在新一行中显示80个‘-’字符。 (4) 最后以一个换行作为结束。
样例输入 复制
Hallo, dies ist eine
ziemlich lange Zeile, die in Html
aber nicht umgebrochen wird.
<br>
Zwei <br> <br> produzieren zwei Newlines.
Es gibt auch noch das tag <hr> was einen Trenner darstellt.
Zwei <hr> <hr> produzieren zwei Horizontal Rulers.
Achtung mehrere Leerzeichen irritieren
Html genauso wenig wie
mehrere Leerzeilen.样例输出 复制
Hallo, dies ist eine ziemlich lange Zeile, die in Html aber nicht umgebrochen
wird.
Zwei
produzieren zwei Newlines. Es gibt auch noch das tag
——————————————————————————–
was einen Trenner darstellt. Zwei
——————————————————————————–
——————————————————————————–
produzieren zwei Horizontal Rulers. Achtung mehrere Leerzeichen irritieren Html
genauso wenig wie mehrere Leerzeilen.
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
char s[10000];
int count = 0;
int flag = 0;
// freopen("4001.txt","r",stdin);
while(~scanf("%s",s)){
int temp = strlen(s);
count += temp + 1;
if(count > 80){
printf("\n");
count = 0;
flag = 1;
}
if(strcmp(s,"<br>")==0&&flag==0){
printf("\n");
count = 0;
flag = 1;
}else if(strcmp(s,"<br>")==0&&flag==1){
printf("\n");
count = 0;
flag = 1;
}
else if(strcmp(s,"<hr>")==0&&flag==0){
printf("\n--------------------------------------------------------------------------------\n");
count = 0;
flag = 1;
}else if(strcmp(s,"<hr>")==0&&flag==1){
printf("--------------------------------------------------------------------------------\n");
count = 0;
flag = 1;
}else{
printf("%s ",s);
flag = 0;
}
}
return 0;
}4002 按错键
题目描述
一种常见的打字错误是将手放在键盘上正确位置的右侧相邻的一位,如下图所示:
键盘示意图
例如,键入“Q”却按成了“W”,“J”被按成“K”,要求你编程对纠正上述的错误
输入
输入文件包含多行,每行可能会包含数字、空格、大写字母(不包括“A”、“Z”、“Q”)和标点符号(不包括单引号“’”)。所有标记了单词的按键不不包括在内,如Tab、BackSpace、Control等。
输出
将每个字母或标点符号用它左边的符号替换,输入中的空格按原样输出。
样例输入 复制
O S,GOMR YPFSU/
234567890-=WERTYYUIOP[]样例输出 复制
I AMFINE TODAY.
1234567890-QWERTTYUIOP[

思路:
乍一看是不是没什么想法,其实就是先把键盘上按键存储下来,之后查表就可以了。注意格式,处理方式用fgets。
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
char str[] = {"`1234567890-=QWERTYUIOP[]ASDFGHJKL;'ZXCVBNM,./"};
char s[2000];
int length = strlen(str);
while(fgets(s,sizeof(s),stdin)){
int len = strlen(s);
for(int i = 0;i < len;i++){
if(s[i] == ' '){
printf(" ");
continue;
}
for(int j = 0;j < length;j++){
if(s[i] == str[j]){
printf("%c",str[j - 1]);
break;
}
}
}
printf("\n");
}
}4003 字符串统计
题目描述
对于给定的一个字符串,统计其中数字字符出现的次数。
输入
输入数据有多行,第一行是一个正整数n,表示测试实例的个数,后面跟着n行,每行包括一个由字母和数字组成的字符串。
输出
对于每个测试实例,输出该串中数值的个数,每个输出占一行。
样例输入 复制
2
asdfasdf123123asdfasdf
asdf111111111asdfasdfasdf样例输出 复制
6
9
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
int n;
char str[10000];
scanf("%d",&n);
for(int t = 1;t <= n;t++){
scanf("%s",str);
int cnt = 0;
int len = strlen(str);
for(int i = 0;i < len;i++){
if(str[i] >= '0' && str[i] <= '9'){
cnt++;
}
}
printf("%d\n",cnt);
}
}4004 开门人和关门人
题目描述
每天第一个到机房的人要把门打开,最后一个离开的人要把门关好。现有一堆杂乱的机房签到、签离记录,请根据记录找出当天开门和关门的人。
输入
测试输入的第一行给出记录的总天数N (N > 0 )。下面列出了N天的记录。每天的记录在第一行给出记录的条目数M ( M > 0 ),下面是M行,每行的格式为: 证件号码 签到时间 签离时间 其中时间按“小时:分钟:秒钟”(各占2位)给出,证件号码是长度不超过15的字符串。
输出
对每一天的记录输出1行,即当天开门和关门人的证件号码,中间用1空格分隔。 注意:在裁判的标准测试输入中,所有记录保证完整,每个人的签到时间在签离时间之前,且没有多人同时签到或者签离的情况。
样例输入 复制
3
1
ME3021112225321 00:00:00 23:59:59
2
EE301218 08:05:35 20:56:35
MA301134 12:35:45 21:40:42
3
CS301111 15:30:28 17:00:10
SC3021234 08:00:00 11:25:25
CS301133 21:45:00 21:58:40样例输出 复制
ME3021112225321 ME3021112225321
EE301218 MA301134
SC3021234 CS301133
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
int n;
char name[101];
char st[10000];
char en[10000];
scanf("%d",&n);
while(n--){
int m;
int i = 0;
int j = 0;
int h;
int s;
int start;
int mini,minn = 1e9;
int end,maxx = -1;
scanf("%d",&m);
for(i = 0;i < m;i++){
scanf("%s %d:%d:%d",name,&h,&mini,&s);
start = h * 3600 + mini * 60 + s;
if(start < minn){
minn = start;
strcpy(st,name);
}
scanf("%d:%d:%d",&h,&mini,&s);
end = h * 3600 + mini * 60 + s;
if(end > maxx){
maxx = end;
strcpy(en,name);
}
}
printf("%s %s\n",st,en);
}
return 0;
}4005 看和说
题目描述
看和说的顺序定义如下:任何一个字符串都是以数字开头,每个随后的元素都是被前一个元素重新定义。例如,字符串“122344111”可以被描述为“1个1,两个2,1个3,2个4和3个1”。因此,122344111以序列的形式表示出来就是1122132431。同理,101就表示1111111111。
输入
输入包括测试数据的组数,然后依次为相应的测试数据,每个数据占一行,不会超过1000位。
输出
对于每个测试数据,输出对应的字符串。
样例输入 复制
3
122344111
1111111111
12345样例输出 复制
1122132431
101
1112131415
代码C语言:
#include <stdio.h>
#include <string.h>
#include <stdio.h>
#include <string.h>
int main(){
char str[1005];
int n;
scanf("%d",&n);
while(n--){
int count = 1;
int i,j;
scanf("%s",str);
int len = strlen(str);
for(i = 0;i < len;i++){
if(str[i]!=str[i+1]){
printf("%d%d",count,str[i]-'0');
count = 1;
}else{
count++;
}
}
printf("\n");
}
return 0;
} }
return 0;
}
4006 A+B问题
题目描述
给定两个整数A和B,其表示形式是:从个位开始,每三位数用逗号,隔开。 现在请计算A+B的结果,并以正常形式输出。
输入
输入包含多组数据,每组数据占一行,由两个整数A和B组成(-109 < A,B < 109)。
输出
请计算A+B的结果,并以正常形式输出,每组数据占一行。
样例输入 复制
-234,567,890 123,456,789
1,234 2,345,678样例输出 复制
-111111101
2346912
思路:
一位一位处理,每次到下一位就乘以10,负号的处理用一个变量记录即可。
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
char a[1000],b[1000];
while(~scanf("%s %s",a,b)){
int len1 = strlen(a);
int len2 = strlen(b);
long long sum1 = 0,sum2 = 0;
int flag = 0;
for(int i = 0;i < len1;i++){
if(a[i] == '-'){
flag = 1;
continue;
}
if(a[i] != ',') {
sum1 += a[i] - '0';
sum1 *= 10;
}
}
sum1 /= 10;
if(flag) sum1 = -sum1;
flag = 0;
for(int i = 0;i < len2;i++){
if(b[i] == '-'){
flag = 1;
continue;
}
if(b[i] != ',') {
sum2 += b[i] - '0';
sum2 *= 10;
}
}
sum2 /= 10;
if(flag) sum2 = -sum2;
flag = 0;
long long sum = sum1 + sum2;
printf("%lld\n",sum);
}
}4007 圆括号编码
题目描述
令S=s1 s2 …sn是一个规则的圆括号字符串。S以2种不同形式编码: (1)用一个整数序列P=p1 p2 … pn编码,pi代表在S中第i个右圆括号的左圆括号数量。(记为P-序列) (2)用一个整数序列W=w1 w2 … wn编码,对每一个右圆括号a,从与之匹配的左圆括号开始到a之间的右圆括号的数目用wi表示。(记为W-序列) 例如: S为:(((()()()))) P-序列 4 5 6 6 6 6 W-序列 1 1 1 4 5 6 编程把一个圆括号串S的P-序列转化为W-序列。
输入
第一行是一个整数t(1 <= t <= 10),表示测试数据的组数。接下来是每组测试数据。每个测试数据的第1行是一个整数n(1 <= n <= 20),第2行是一个圆括号串的P-序列,包含n个正整数,以空格隔开。
输出
输出t行,对每个测试数据所表示的P-序列,输出对应的W-序列,占一行,包含n个整数。
样例输入 复制
3
5
4 5 5 5 5
6
4 5 6 6 6 6
9
4 6 6 6 6 8 9 9 9样例输出 复制
1 1 3 4 5
1 1 1 4 5 6
1 1 2 4 5 1 1 3 9
思路:
这道题实现起来挺麻烦的。思路就是先把P-序列转换成S圆括号字符串,再把S字符串转换成W-序列。
第一部分【把P-序列转换成S圆括号字符串】,就是先读入P-序列,然后我们知道了第 i 个右括号左边有多少个左括号,所以就用个字符数组,把左括号放上,假设第5个右括号左边有6个左括号,第6个右括号左边有7个左括号,不就说明第5个和第6个右括号之间有1个左括号嘛。所以就是按照这个思路去模拟,每次放上 s[ i ] – s[ i – 1 ] 个左括号,再放上右括号就完成了模拟。
第二部分【把S字符串转换成W-序列】,这个也比较麻烦。思路就是每次遇到一个右括号,就往它的左边去找和它对应的那个左括号,找到就皆大欢喜。那找的途中记录右括号数目和左括号数目,如果数目相同说明中间这一段匹配上了,那就输出匹配数即可。
是一个比较绕的模拟,详情看下方代码。
代码C语言:
#include <stdio.h>
#include <string.h>
int main() {
int t;
scanf(“%d”, &t);
int p[10000];
#include <stdio.h>
#include <string.h>
int main() {
int t;
scanf("%d", &t);
int p[10000];
while (t--) {
int n;
char s[10000] = {0};
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf("%d", &p[i]);
}
//先转换成S字符串
int idx = 0;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= p[i] - p[i - 1]; j++) {
s[idx++] = '(';
}
s[idx++] = ')';
}
s[idx] = '\0';
//再转换成W序列
int cnt = 1;
int cnt1 = 0,cnt2 = 0;
for(int i = 0;i < idx;i++){
//遇到右括号,就去找它对应的左括号,并且计数一下中间有多少个右括号
if(s[i] == ')'){
cnt2 = 1;
cnt1 = 0;
for(int j = i - 1;j >= 0;j--){
if(s[j] == '(') {
cnt1++;
}else {
cnt2++;
}
if(cnt1 == cnt2){
printf("%d ",cnt2);
break;
}
}
}
}
printf("\n");
}
}
4008 在线评判系统
题目描述
李四正在建设一个在线评判系统,目前他万事俱备,只欠评判系统。评判系统必须去读正确数据文件和用户数据文件,然后比对这两个文件。如果这两个文件完全一样,系统返回“Accepted”,否则如果两个文件只是空格,tab键或换行有所区别的话,则返回“Presentation Error”,否则系统将返回“Wrong Answer”。 给定正确数据文件和用户结果文件,你的任务就是决定系统应该返回什么判断。
输入
输入包括多组测试数据。第一行是整数T,表示测试数据的组数。接下来是T个测试数据。每个测试数据包括两个部分,正确的输出文件和用户结果文件。它们都是以一个单独的字符串“START”占一行表示开始。最后以字符串“END”表示结束。所有的数据都是在这两个字符串之间。所有的数据不超过5000个字符。
输出
对于每个测试数据,输出评判系统应该返回的值。
样例输入 复制
4
START
1 + 2 = 3
END
START
1+2=3
END
START
1 + 2 = 3
END
START
1 + 2 = 3
END
START
1 + 2 = 3
END
START
1 + 2 = 4
END
START
1 + 2 = 3
END
START
1 + 2 = 3
END样例输出 复制
Presentation Error
Presentation Error
Wrong Answer
Presentation Error
思路:
很麻烦的一道字符串模拟题,基本思路就是用scanf去读begin肯定是能读到的,然后就一直去用fgets读end,没读到end之前,就拼接字符串,就是我们得到的两个用来比较的字符串。然后去把两个字符串做比较,相同就AC,不同的话就去掉空格和换行进行第二轮比较,如果一样就是PE,否则就是WA。
代码C语言:
#include<stdio.h>
#include<string.h>
//因为会把空格和换行什么读入,会影响到END的判断,所以这边单独写了个判断函数
int judge(char a[]){
if(a[0] == 'E' && a[1] == 'N' && a[2] == 'D'){
return 1;
}
return 0;
}
int main(){
int t;
scanf("%d",&t);
while(t--){
char begin[1000];
char str1[1000] = {0};
char str2[1000] = {0};
char end[1000] = {0};
int len1 = 0;
int len2 = 0;
int cnt = 0;
//读入BEGIN
scanf("%s",begin);
getchar();
//读入字符串+END
while(fgets(end,sizeof(end),stdin)){
if(judge(end)) break;
if(strlen(end) != 0){
strcat(str1,end);
len1 = strlen(str1);
}
}
//读入BEGIN
scanf("%s",begin);
getchar();
//读入字符串+END
while(fgets(end,sizeof(end),stdin)){
if(judge(end)) break;
if(strlen(end) != 0){
strcat(str2,end);
len2 = strlen(str2);
}
}
//做第一轮比较
if(strcmp(str1,str2) == 0){
printf("Accepted\n");
}else{
//开始第二轮比较
char temp1[100] = {'\0'};
char temp2[100] = {'\0'};
int j = 0;
//去除 空格 换行 和 tab
for(int i = 0;i < len1;i++){
if(str1[i] != ' ' && str1[i] != '\n' && str1[i] != '\t'){
temp1[j++] = str1[i];
}
}
temp1[j] = '\0';
j = 0;
//去除 空格 换行 和 tab
for(int i = 0;i < len2;i++){
if(str2[i] != ' ' && str2[i] != '\n' && str2[i] != '\t'){
temp2[j++] = str2[i];
}
}
temp2[j] = '\0';
//第二轮比较
if(strcmp(temp1,temp2) == 0){
printf("Presentation Error\n");
}else{
printf("Wrong Answer\n");
}
}
}
}4009 令人惊讶的字符串
题目描述
字符串S由字母字符组成,它的“D-对字符串”为S中相隔D个位置的两个字符组成的有序对。如果S所有的“D-对字符串”都不相同,则称S是“D-唯一的”。如果S对所有可能的D值都是“D-唯一的”,则称S是一个“令人惊讶的字符串”。 例如,字符串ZGBG,它的“0-对字符串”为ZG、GB和BG,由于这三个字符串都不相同,因此ZGBG是“0-唯一的”。同样,它的“1-对字符串”为ZB和GG,不相同,也是“1-唯一的”。最后,它的“2-对字符串”只有一个,就是ZG,因此ZGBG也是“2-唯一的”。 因此,ZGBG是一个“令人惊讶的字符串”。
输入
输入文件中包含了若干个非空字符串,由大写字母字符组成,长度最长为79个字符。每个字符串占一行。输入文件的最后一行为“*”字符,代表输入结束。
输出
输入文件中包含了若干个非空字符串,由大写字母字符组成,长度最长为79个字符。每个字符串占一行。输入文件的最后一行为“*”字符,代表输入结束。
样例输入 复制
ZGBG
X
EE
AAB
AABA
AABB
BCBABCC
*样例输出 复制
ZGBG is surprising.
X is surprising.
EE is surprising.
AAB is surprising.
AABA is surprising.
AABB is NOT surprising.
BCBABCC is NOT surprising.
思路:
枚举所有可能的k。字符串用双层遍历去做比较这件事大家应该都会吧?我们再往里面加一层循环,用来枚举k的值,然后把 i 和 j 还有 i + k 和 j + k 做比较,如果两对都相同,说明不是令人惊讶的字符串。
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
char str[1000];
int i,j,k;
while(scanf("%s",str)){
int flag = 0;
if(str[0]=='*') break;
int len = strlen(str);
for(i = 0;i < len;i++){
for(j = i+1 ;j < len;j++){
if(str[i] == str[j]){
for(k = 1;k < len;k++){
if(str[i + k] == str[j + k] && i+k<len&&j+k<len){
flag = 1;
break;
}
}
}
}
}
if(flag == 0){
printf("%s is surprising.\n",str);
}else{
printf("%s is NOT surprising.\n",str);
}
}
return 0;
}4010 古代密码
题目描述
古罗马帝王有一个包括各种部门的强大政府组织。其中有一个部门就是保密服务部门。为了保险起见,在省与省之间传递的重要文件中的大写字母是加密的。当时最流行的加密方法是替换和重新排列。 替换方法是将所有出现的字符替换成其它的字符。有些字符会碰巧替换成它自己。例如:替换规则可以是将A 到 Y替换成它的下一个字符,将Z替换成 A,如果原词是 VICTORIOUS 则它变成 WJDUPSJPVT。 排列方法改变原来单词中字母的顺序。例如:将顺序 <2, 1, 5, 4, 3, 7, 6, 10, 9, 8> 应用到 VICTORIOUS 上,则得到IVOTCIRSUO。 人们很快意识到单独应用替换方法或排列方法,加密是很不保险的。但是如果结合这两种方法,在当时就可以得到非常可靠的加密方法。所以,很多重要信息先使用替换方法加密,再将加密的结果用排列的方法加密。用两种方法结合就可以将VICTORIOUS 加密成JWPUDJSTVP。 考古学家最近在一个石台上发现了一些信息。初看起来它们毫无意义,所以有人设想它们可能是用替换和排列的方法被加密了。人们试着解读了石台上的密码,现在他们想检查解读的是否正确。他们需要一个计算机程序来验证她,你的任务就是写这个验证程序。
输入
输入有两行。第一行是石台上的文字。文字中没有空格,并且只有大写英文字母。第二行是被解读出来的加密前的文字。第二行也是由大写英文字母构成的。这两行字符数目的长度都不超过计划100。
输出
如果第二行经过某种加密方法后可以产生第一行的信息,输出 YES,否则输出NO。
样例输入 复制
JWPUDJSTVP
VICTORIOUS样例输出 复制
YES
思路:
模拟加密过程,先移位然后再调换顺序即可。移位很好实现,怎么做到排列呢?我们统计字符个数,假设第一个字符串用到的字符和第二个字符串用到的字符是一致的,说明第二个字符串排列后肯定能得到第一个字符串。
原本笔者以为这道题需要把三种加密方式都考虑一次【替换、排列、替换+排列】,后面经过笔者测试,只需要考虑 替换+排列 这一种加密方式即可,请放心食用。
代码C语言:
#include<stdio.h>
#include<string.h>
int vis1[100];
int vis2[100];
int main(){
char a[100],b[100];
char c[100];
scanf("%s",a);
scanf("%s",b);
int len1 = strlen(a);
int len2 = strlen(b);
if(len2 != len1) {
printf("NO\n");
return 0;
}
for(int i = 0;i < len2;i++){
b[i] = b[i] + 1;
if(b[i] > 'Z') b[i] = 'A';
vis2[b[i] - 'A']++;
}
for(int i = 0;i < len1;i++){
vis1[a[i] - 'A']++;
}
for(int i = 0;i < 26;i++){
if(vis1[i] != vis2[i]){
printf("NO\n");
return 0;
}
}
printf("YES\n");
}4011 检验和
题目描述
检验和是一种算法,这种算法扫描数据包并返回一个值。这种算法的思想是当数据包被改变时,校验和同样要改变,因此校验和通常用来检查传输错误,用来确认传输内容的正确性。 在本题中,你需要实现一种校验和算法,称为Quicksum,一个Quicksum数据包只允许包含大写字母和空格,并且起始字符和终止字符都是大写字母。除此之外,空格和大写字母允许以任何的组合方式出现,包括连续的空格。 校验和Quicksum是数据包中所有字符在数据包中的位置和它的值的乘积的累加和。空格的值为0,其他大写字母的值为它在字母表中的位置,即A=1,B=2,……,Z=26。 下面是Quicksum数据包“ACM”和“MID CENTRAL”的校验和计算方法: ACM:1 * 1 + 2 * 3 + 3 * 13 = 46 MID CENTRAL:1 * 13 + 2 * 9 + 3 * 4 + 4 * 0 + 5 * 3 + 6 * 5 + 7 * 14 + 8 * 20 + 9 * 18 + 10 * 1 + 11 * 12 = 650
输入
输入文件包括一个或多个数据包,输入文件的最后一行为符号#,表示输入文件结束。每个数据包占一行,每个数据包不会以空格开头或结尾,每个数据包包含1~255个字符。
输出
对每个数据包,输出一行,为它的校验和。
样例输入 复制
ACM
MID CENTRAL
REGIONAL PROGRAMMING CONTEST
ACN
A C M
ABC
BBC
#样例输出 复制
46
650
4690
49
75
14
15
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
char str[1000];
while(fgets(str,sizeof(str),stdin)){
if(str[0] == '#') break;
int len = strlen(str);
int sum = 0;
for(int i = 0;i < len;i++){
if(str[i] >= 'A' && str[i] <= 'Z')
sum += (i + 1) * (str[i] - 'A' + 1);
}
printf("%d\n",sum);
}
}4012 摩尔斯编码
题目描述
摩尔斯编码采用变长的点号“.”和短划线“-”序列来代表字符。实际编码时,电文中的字符用空格隔开。表4.1是摩尔斯编码中各字符对应的编码。
注意,在上表中点号和短划线有4个组合没有采用。在本题中,将这四种组合分配给以下的字符: 下划线:..– 点号:—. 逗号:.-.- 问号:—- 因此,电文“ACM_GREATER_NY_REGION”被编码为:.- -.-. — ..– –. .-. . .- – . .-. ..– -. -.– ..– .-. . –. .. — -. Ohaver基于摩尔斯编码提出了一种加密方法。这种方法的思路是去掉字符间的空格,并且在编码后给出每个字符编码的长度。例如电文“ACM”编码为“.–.-.–242”。 Ohaver的加密(解密也是一样的)方法分为3个步骤: (1)将原文转换成摩尔斯编码,去掉字符间的空格,然后把每个字符长度的信息添加在后面; (2)将表示各字符长度的字符串反转; (3)按照反转后的各字符长度,解释点号和短划线序列,得到密文。 例如,假设密文为“AKADTOF_IBOETATUK_IJN”,解密步骤如下: (1)将密文转换为摩尔斯编码,去掉字符间的空格,添加各字符长度组成的字符串,得到“.–.-.–..—-..-…–..-…—.-.–..–.-..–…—-.232313442431121334242”; (2)将字符长度字符串反转,得到“242433121134244313232”; (3)对字符长度字符串反转后的编码字符串,用摩尔斯编码解释该字符串,得到原文“ACM_GREATER_NY_REGION”。 本题目的目的是实现Ohaver的解密算法。
输入
输入文件中包含多个测试数据。输入文件的第1行是一个整数n,表示测试数据的个数。每个测试数据占一行,为一个用Ohaver加密算法加密后的密文。每个密文中允许出现的符号为:大写字母,下划线、逗号,点号和问号。密文长度不超过100个字符。
输出
对输入文件中的每个密文,首先输出密文的序号,然后是冒号和空格,最后是解码后的原文。
样例输入 复制
5
AKADTOF_IBOETATUK_IJN
PUEL
QEWOISE.EIVCAEFNRXTBELYTGD.
?EJHUT.TSMYGW?EJHOT
DSU.XFNCJEVE.OE_UJDXNO_YHU?VIDWDHPDJIKXZT?E样例输出 复制
1: ACM_GREATER_NY_REGION
2: PERL
3: QUOTH_THE_RAVEN,_NEVERMORE.
4: TO_BE_OR_NOT_TO_BE?
5: THE_QUICK_BROWN_FOX_JUMPS_OVER_THE_LAZY_DOG
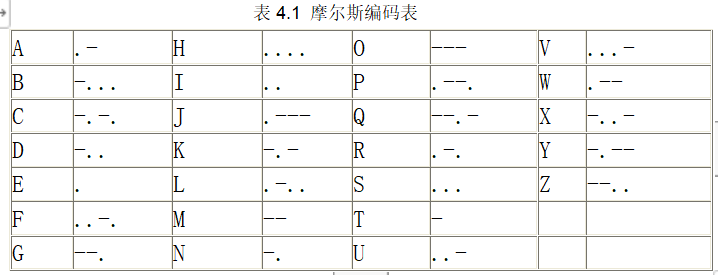
思路:
这道题思路不难想,就是真的很恶心。一步一步跟着题目模拟就好,但是真的要费点功夫。下方代码写得很清楚了,自行参考~
strncpy函数或者memcpy函数可以去了解一下!
c++的string用substr函数~
代码C语言:
#include<stdio.h>
#include<string.h>
int cnt;
int num[1000];
char stable[35][35] = {".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."};
int number[30] = {2,4,4,3,1,4,3,4,2,4,3,4,2,2,3,4,4,3,3,1,3,4,3,4,4,4};
void reverse(){
for(int i = 0;i < cnt/2;i++){
int t = num[i];
num[i] = num[cnt - i - 1];
num[cnt - i - 1] = t;
}
}
void find(char str[]){
for(int i = 0;i < 26;i++){
if(strcmp(str,stable[i]) == 0){
printf("%c",'A' + i);
return ;
}
}
if(strcmp(str,"..--") == 0){
printf("_");
}else if(strcmp(str,"---.") == 0){
printf(".");
}else if(strcmp(str,".-.-") == 0){
printf(",");
}else if(strcmp(str,"----") == 0){
printf("?");
}
}
int main(){
char str[1000];
int n;
scanf("%d",&n);
int t = 0;
while(n--){
t++;
char s[1000] = {'\0'};
cnt = 0;
scanf("%s",str);
int len = strlen(str);
//获取摩斯电码字符串
for(int i = 0;i < len;i++){
if(str[i] >= 'A' && str[i] <= 'Z'){
strcat(s,stable[str[i] - 'A']);
}else{
if(str[i] == '?'){
strcat(s,"----");
}else if(str[i] == ','){
strcat(s,".-.-");
}else if(str[i] == '.'){
strcat(s,"---.");
}else if(str[i] == '_'){
strcat(s,"..--");
}
}
}
//获取原始数字串
for(int i = 0;i < len;i++){
cnt++;
if(str[i] >= 'A' && str[i] <= 'Z')
num[i] = number[str[i] - 'A'];
else{
num[i] = 4;
}
}
//获取翻转数字串
reverse();
//用数字串和字符串开始解密
int sum = 0;
printf("%d: ",t);
for(int i = 0;i < cnt;i++){
char temp[100] = {'\0'};
//要截取sum和sum + num[i]之间的字符串
strncpy(temp,s + sum,num[i]);//一个可以截取部分字符串的函数
sum += num[i];
//把截取的字符串在stable数组里寻找,找到就输出
find(temp);
}
printf("\n");
}
}4013 anagrammatic距离
题目描述
两个单词互为anagrams,意思是一个单词的字母经过重新排序后可以形成另一个单词,例如,单词“occurs”和“succor”互为anagrams。然而“dear”和“dared”不是互为anagrams,因为字母d在“dared”中出现了2次,而在“dear”只出现了1次。英语中最著名的anagrams是“dog”和“god”。 两个单词的anagrammatic距离为N,意思是至少要在两个单词中一共去掉N个字母,才能使两个单词中剩下的部分互为anagrams。例如,给定两个单词:“sleep”和“leap”,我们需要至少去掉3个字母(从单词“sleep”中去掉2个字母、从单词“leap”中去掉1个字母),才能使这两个单词中剩下的部分互为anagrams(每个单词只剩下lep)。对于单词“dog”和“cat”,由于两个单词没有相同的字母,所以它们的anagrammatic距离是两个单词字母个数的总和,因为要去掉所有字母才能使它们互为anagrams。(注意:一个单词总是和它本身互为anagrams的) 你的任务是编写一个程序,计算两个单词的anagrammatic距离。
输入
输入文件的第一行为一个正整数N(N < 60000),标明输入文件中测试数据的个数。每个测试数据包含两个单词,有可能为空,每个单词占一行(所以有可能为空行)。因此输入文件中第一行之后还有2N行。 尽管单词可能为空,但它们肯定是很简单的单词(单词中的字母都是小写的),而且都是英文字母表中26个字母中的一个,最长的单词是pneumonoultramicroscopicsilicovolcanoconiosis。
输出
对每个测试数据,输出两个单词的anagrammatic距离,按照输出样例中的格式输出。
样例输入 复制
4
crocus
succor
dares
seared
emptysmell
lemon样例输出 复制
Case #1: 0
Case #2: 1
Case #3: 5
Case #4: 4
思路:
注意输出格式,还有fgets会把换行符也读入进来,可以稍稍处理一下。基本思路就是计数,看看26个字母的个数,看看两边差多少,然后把差值求和就是答案了。
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
int n;
scanf("%d",&n);
getchar();
int t = 0;
while(n--){
t++;
printf("Case #%d: ",t);
char a[1000];
char b[1000];
int vis1[100] = {0};
int vis2[100] = {0};
fgets(a,sizeof(a),stdin);
fgets(b,sizeof(b),stdin);
int len1 = strlen(a);
int len2 = strlen(b);
if(a[len1 - 1] == '\n') a[len1 - 1] = '\0';
if(b[len2 - 1] == '\n') b[len2 - 1] = '\0';
len1 = strlen(a);
len2 = strlen(b);
for(int i = 0;i < len1;i++){
vis1[a[i] - 'a']++;
}
for(int i = 0;i < len2;i++){
vis2[b[i] - 'a']++;
}
int sum = 0;
for(int i = 0;i < 26;i++){
sum += abs(vis1[i] - vis2[i]);
}
printf("%d\n",sum);
}
}4101 统计字符数
题目描述
判断一个由a~z这26个字符组成的字符串中哪个字符出现的次数最多。
输入
第1行是测试数据的组数n,每组测试数据占1行,是一个由a-z这26个字符组成的字符串,每组测试数据之间有一个空行,每行数据不超过1000个字符且非空。
输出
n行,每行输出对应一个输入。一行输出包括出现次数最多的字符和该字符出现的次数,中间是一个空格。 如果有多个字符出现的次数相同且最多,那么输出ASCII码最小的那一个字符。
样例输入 复制
2
abbcccadfadffasdf
样例输出 复制
c 3
f 4
代码C语言:
#include<stdio.h>
#include<string.h>
int vis[100];
int main()
{
int n;
scanf("%d",&n);
while(n--){
memset(vis,0,sizeof(vis));
char str[100];
scanf("%s",str);
int len = strlen(str);
for(int i = 0;i < len;i++){
vis[str[i] - 'a']++;
}
int maxx = 0;
int index = 0;
for(int i = 0;i < 26;i++){
if(vis[i] > maxx){
maxx = vis[i];
index = i;
}
}
printf("%c %d\n",index + 'a',maxx);
}
}4102 气球升起来
题目描述
又到一年竞赛时,每当看到气球升起来,是多么令人兴奋呀。告诉你一个秘密,裁判总是热衷于猜哪题是最流行的题。比赛结束后,只要统计一下所有的气球颜色就能得到答案。 今年,他们决定把这个工作留给你来完成。
输入
输入包括多组测试样例,每个测试数据都是以数字N开始 (0 < N <= 1000) ,它标识分发的气球总数。接下来的N行就是不同颜色的气球,气球颜色是一个不超过15个字符的字符串。 当N=0时表示输入结束。
输出
对于每组数据,输出最流行的问题对应的颜色。这里保证每个测试数据只会有一个答案。
样例输入 复制
5
green
red
blue
red
red
3
pink
orange
pink
0样例输出 复制
red
pink
思路:
遍历去找哪个字符串出现次数最多,下方代码是一种解决办法,读者也可以采取别的思路~
代码C语言:
#include<stdio.h>
#include<string.h>
int vis[1000];
int main(){
int n;
while(~scanf("%d",&n)){
if(!n) break;
char str[100][100] = {'\0'};
memset(vis,0,sizeof(vis));
char temp[100];
for(int i = 1;i <= n;i++)
scanf("%s",str[i]);
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
if(strcmp(str[i],str[j]) == 0){
vis[i]++;
}
}
}
int maxx = 0;
int index = 0;
for(int i = 1;i <= n;i++){
if(vis[i] > maxx){
maxx = vis[i];
index = i;
}
}
printf("%s\n",str[index]);
}
}4103 All in All
题目描述
给定两个字符串s和t,判断s是否是t的子序列。即从t中删除一些字符,将剩余的字符连接起来,即可获得s。
输入
输入文件包括多组测试数据,每组测试数据占一行,包括两个由ASCII码组成的字符串s和t,它们的长度都不超过100000。
输出
对于每个测试数据输出一行,如果s是t的子序列,则输出“Yes”,否则输出“No”。
样例输入 复制
sequence subsequence
person compression
VERDI vivaVittorioEmanueleReDiItalia
caseDoesMatter CaseDoesMatter样例输出 复制
Yes
No
Yes
No
代码C语言:
#include<stdio.h>
#include<string.h>
char a[100005];
char b[100005];
int main(){
while(~scanf("%s %s",a,b)){
int flag = 0;
int len1 = strlen(a);
int len2 = strlen(b);
if(len1 > len2) {
printf("No\n");
continue;
}
int i,j;
for(i = 0,j = 0;i < len1 && j < len2;j++){
if(a[i] == b[j]){
i++;
}
}
if(i == len1){
printf("Yes\n");
}else{
printf("No\n");
}
}
}4104 Soundex编码
题目描述
Soundex编码是根据单词的拼写和发音相似性来对单词进行分组,例如,“can”与“khawn”, “con”与“gone”在Soundex编码下是相同的。 Soundex编码方法将每个单词转换成一串数字,每个数字代表一个字母。具体如下: 1 表示B、F、P或V; 2 表示C、G、J、K、Q、S、X或Z; 3 表示D或T; 4 表示L; 5 表示M或N; 6 表示R。 字母A,E,I,0,U,H,W和Y在Soundex中不用编码的,可以直接忽略。相邻的并且具有相同编码值的字母只用一个对应的数字表示。具有相同Soundex编码值的单词被认为是相同的单词。
输入
输入文件中的每行为一个单词,全部大写,不超过20个字母。
输出
对输入文件中的每个单词,输出该单词的Soundex编码,占一行。
样例输入 复制
KHAWN
PFISTER
BOBBY样例输出 复制
25
1236
11
代码C语言:
#include <stdio.h>
#include <string.h>
int main(){
char str[1000];
while(~scanf("%s",str)){
int i;
int n = strlen(str);
int flag[8]={0};
for(i = 0;i < n;i++){
switch(str[i]){
case 'B':
case 'F':
case 'P':
case 'V':if(flag[1]==0)printf("1");flag[1]=1;flag[2]=0;flag[3]=0;flag[4]=0;flag[5]=0;flag[6]=0;break;
case 'C':
case 'G':
case 'J':
case 'K':
case 'Q':
case 'S':
case 'X':
case 'Z':if(flag[2]==0)printf("2");flag[1]=0;flag[2]=1;flag[3]=0;flag[4]=0;flag[5]=0;flag[6]=0;break;
case 'D':
case 'T':if(flag[3]==0)printf("3");flag[1]=0;flag[2]=0;flag[3]=1;flag[4]=0;flag[5]=0;flag[6]=0;break;
case 'L':if(flag[4]==0)printf("4");flag[1]=0;flag[2]=0;flag[3]=0;flag[4]=1;flag[5]=0;flag[6]=0;break;
case 'M':
case 'N':if(flag[5]==0)printf("5");flag[1]=0;flag[2]=0;flag[3]=0;flag[4]=0;flag[5]=1;flag[6]=0;break;
case 'R':if(flag[6]==0)printf("6");flag[1]=0;flag[2]=0;flag[3]=0;flag[4]=0;flag[5]=0;flag[6]=1;break;
default:flag[1]=0;flag[2]=0;flag[3]=0;flag[4]=0;flag[5]=0;flag[6]=0;break;
}
}
printf("\n");
}
return 0;
} 4111 浮点数格式
题目描述
输入n个浮点数,要求把这n个浮点数重新排列后再输出。
输入
第1行是一个正整数n(n <= 10000),后面n行每行一个浮点数,保证小数点会出现, 浮点数的长度不超过50位,注意这里的浮点数会超过系统标准浮点数的表示范围。
输出
n行,每行对应一个输入。要求每个浮点数的小数点在同一列上,同时要求首列上不会全部是空格。
样例输入 复制
2
-0.34345
4545.232样例输出 复制
-0.34345
4545.232
代码C语言:
#include<stdio.h>
#include<string.h>
char a[10005][100];
int index[10005];
int max(int a,int b){
return a > b ? a : b;
}
int main(){
int n;
scanf("%d",&n);
int len = 0;
int maxx = 0;
for(int i = 1;i <= n;i++){
scanf("%s",a[i]);
len = strlen(a[i]);
for(int j = 0;j < len;j++){
if(a[i][j] == '.') index[i] = j;
}
maxx = max(maxx,index[i]);
}
for(int i = 1;i <= n;i++){
for(int j = 1;j <= maxx - index[i];j++){
printf(" ");
}
puts(a[i]);
}
}4112 487-3279
企业喜欢用容易被记住的电话号码。让电话号码容易被记住的一个办法是将它写成一个容易记住的单词或者短语。例如,你需要给滑铁卢大学打电话时,可以拨打TUT-GLOP。有时,只将电话号码中部分数字拼写成单词。当你晚上回到酒店,可以通过拨打310-GINO来向Ginos订一份pizza。让电话号码容易被记住的另一个办法是以一种好记的方式对号码的数字进行分组。通过拨打必胜客的“三个十”号码3-10-10-10,你可以从他们那里订pizza。 电话号码的标准格式是七位十进制数,并在第三、第四位数字之间有一个连接符。电话拨号盘提供了从字母到数字的映射,映射关系如下: A、B和C映射到2 D、E和F映射到3 G、H和I映射到4 J、K和L映射到5 M、N和O映射到6 P、R和S映射到7 T、U和V映射到8 W、X和Y映射到9 Q和Z没有映射到任何数字,连字符不需要拨号,可以任意添加和删除。 TUT-GLOP的标准格式是888-4567,310-GINO的标准格式是310-4466,3-10-10-10的标准格式是310-1010。 如果两个号码有相同的标准格式,那么他们就是等同的(相同的拨号)。 你的公司正在为本地的公司编写一个电话号码薄。作为质量控制的一部分,你想要检查是否有两个和多个公司拥有相同的电话号码。
输入
输入的格式是,第一行是一个正整数,指定电话号码薄中号码的数量(最多100000)。余下的每行是一个电话号码。每个电话号码由数字,大写字母(除了Q和Z)以及连接符组成。每个电话号码中只会刚好有7个数字或者字母。
输出
对于每个出现重复的号码产生一行输出,输出是号码的标准格式紧跟一个空格然后是它的重复次数。如果存在多个重复的号码,则按照号码的字典升序输出。如果输入数据中没有重复的号码,输出一行: No duplicates.
样例输入 复制
12
4873279
ITS-EASY
888-4567
3-10-10-10
888-GLOP
TUT-GLOP
967-11-11
310-GINO
F101010
888-1200
-4-8-7-3-2-7-9-
487-3279
代码C语言:
#include <stdio.h>
#include <string.h>
char str[100005][100];
char str2[100005][100];
int count[10000005]={0};
int tonum(char p[]){
int sum = 0;
sum += (p[0]-'0')*1000000+(p[1]-'0')*100000+(p[2]-'0')*10000+(p[3]-'0')*1000+(p[4]-'0')*100+(p[5]-'0')*10+(p[6]-'0');
return sum;
}
int main(){
int n;
int i,j,k,p,q,len,t;
scanf("%d",&n);
for(i = 0;i < n;i++){
t = 0;
scanf("%s",str[i]);
len = strlen(str[i]);
for(j = 0;j < len;j++){
switch(str[i][j]){
case 'A':
case 'B':
case 'C':str[i][j] = '2';break;
case 'D':
case 'E':
case 'F':str[i][j] = '3';break;
case 'G':
case 'H':
case 'I':str[i][j] = '4';break;
case 'J':
case 'K':
case 'L':str[i][j] = '5';break;
case 'M':
case 'N':
case 'O':str[i][j] = '6';break;
case 'P':
case 'R':
case 'S':str[i][j] = '7';break;
case 'T':
case 'U':
case 'V':str[i][j] = '8';break;
case 'W':
case 'X':
case 'Y':str[i][j] = '9';break;
}
}
for(k = 0;k < len;k++){
if(str[i][k]>='0'&&str[i][k]<='9'){
str2[i][t++] = str[i][k];
}
}
}
for(i = 0;i < n;i++){
int a = tonum(str2[i]);
count[a]++;
}
for(i = 1000000;i < 10000000;i++){
if(count[i]>1){
//printf("%c%c%c-%c%c%c%c %d\n",str2[i][0],str2[i][1],str2[i][2],str2[i][3],str2[i][4],str2[i][5],str2[i][6],count[j]);
printf("%d%d%d-%d%d%d%d %d\n",i/1000000,(i)/100000%10,i/10000%10,i/1000%10,i/100%10,i/10%10,i%10,count[i]);
}
}
// for(p = 0;p < n;p++){
// puts(str2[p]);
// for(q = p+1;q < n;q++){
// if(strcmp(str2[p],str2[q])==0){
// count[p]++;
// }
// }
// }
// for(i = 0;i < n;i++){
// if(count[i]>1){
// printf("%s %d\n",str2[i],count[i]);
// }
// }
return 0;
} 4113 粗心的打字员
题目描述
Tony是一个粗心的打字员,他总是犯同样的错误。更糟糕的是,光标键坏了,因此他只能用退格键回到出错的地方,纠正以后,原来正确字符还得重新输入。 现在让我们帮助Tony找出至少需要多长时间才能纠正他的错误。
输入
输入文件的第一行是一个整数N,表示测试数据的组数。接下来有N组测试数据。 每组测试数据占3行: 第1行是一个正整数t(t <= 100),表示Tony删除或者输入一个字符所花的时间。 第2行是正确的文本内容。 第3行是Tony输入的文本内容。 注意:文本包含都是可读字符。每行文本长度不超过80。
输出
对每组测试数据,输出为Tony纠正错误所花的最少时间,占一行。
样例输入 复制
2
1
WishingBone
WashingBone
1
Oops
Oooops样例输出 复制
20
6
思路:
大家可以发现一个事情,就是如果我要更改一个字符串,就要把我打错的那些全都删了。从哪开始删?从哪里打错就从哪里开始删。所以我们会发现,前缀相同的部分不用动,我们要改的就是后面不同的部分。所以我们算一下不用动的前缀长度,然后简单模拟一下就好。
代码C语言:
#include <stdio.h>
#include <string.h>
int min(int x,int y){
return x<y?x:y;
}
char str1[10005];
char str2[10005];
int main(){
int n;
int i,j;
scanf("%d",&n);
while(n--){
int t;
scanf("%d",&t);
scanf("%s",str1);
scanf("%s",str2);
int l1 = strlen(str1);
int l2 = strlen(str2);
int same = 0;
int l = min(l1,l2);
for(i = 0;i < l;i++){
if(str1[i]==str2[i]){
same++;
}else{
break;
}
}
printf("%d\n",(l2-same+l1-same)*t);
}
return 0;
} 4114 单词逆序
题目描述
对于每个单词,在不改变这些单词之间的顺序下,逆序输出每个单词。 这个问题包括多组测试数据。第1行是一个整数M,紧接着是一个空行,然后是M组测试数据,每组数据之间有一个空行。要求输出M个输出块。每个输出块之间有一个空行。
输入
第1行为一个整数M,表示测试数据的组数。然后是一个空行,紧接着是M组测试数据,每组测试数据开始是一个正整数N,再是N行测试数据,包含若干个单词,单词之间用一个空格隔开,每个单词仅由大小写字母字符组成。
输出
对每组数据中的每个测试数据,输出一行。
样例输入 复制
1
3
I am happy today
To be or not to be
I want to win the practice contest样例输出 复制
I ma yppah yadot
oT eb ro ton ot eb
I tnaw ot niw eht ecitcarp tsetnoc
代码C语言:
#include <stdio.h>
#include <string.h>
void reverse(int x,int y,char str[]){
int i;
for(i = y;i >= x;i--){
printf("%c",str[i]);
}
}
int main(){
char str[10000];
int m;
int n;
int i;
scanf("%d",&m);
getchar();
while(m--){
scanf("%d",&n);
getchar();
while(n--){
fgets(str,sizeof(str),stdin);
int index1 = 0,index2;
int len = strlen(str);
str[len - 1] = '\0';
for(i = 0;i <= len;i++){
if(str[i]==' '||str[i]=='\0'){
index2 = i - 1;
reverse(index1,index2,str);
index1 = i + 1;
printf(" ");
}
}
printf("\n");
}
printf("\n");
}
return 0;
} 4201 凯撒密码
题目描述
Julius Caesar 生活在充满危险和阴谋的年代。为了生存,他首次发明了密码,用于军队的消息传递。假设你是Caesar 军团中的一名军官,需要把Caesar 发送的消息破译出来、并提供给你的将军。消息加密的办法是:对消息原文中的每个字母,分别用该字母之后的第5个字母替换(例如:消息原文中的每个字母A都分别替换成字母F),其他字符不 变,并且消息原文的所有字母都是大写的。 密码字母:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 原文字母:V W X Y Z A B C D E F G H I J K L M N O P Q R S T U
输入
最多不超过100个数据集组成。每个数据集由3部分组成: 起始行:START 密码消息:由1到200个字符组成一行,表示Caesar发出的一条消息 结束行:END
输出
每个数据集对应一行,是Caesar 的原始消息。
样例输入 复制
START
NS BFW, JAJSYX TK NRUTWYFSHJ FWJ YMJ WJXZQY TK YWNANFQ HFZXJX
END
START
N BTZQI WFYMJW GJ KNWXY NS F QNYYQJ NGJWNFS ANQQFLJ YMFS XJHTSI NS WTRJ
END
START
IFSLJW PSTBX KZQQ BJQQ YMFY HFJXFW NX RTWJ IFSLJWTZX YMFS MJ
END
ENDOFINPUT样例输出 复制
IN WAR, EVENTS OF IMPORTANCE ARE THE RESULT OF TRIVIAL CAUSES
I WOULD RATHER BE FIRST IN A LITTLE IBERIAN VILLAGE THAN SECOND IN ROME
DANGER KNOWS FULL WELL THAT CAESAR IS MORE DANGEROUS THAN HE
代码C语言:
#include<stdio.h>
#include<string.h>
int main()
{
char str[1000];
int i;
while(gets(str))
{
if(strcmp(str,"START")==0){
continue;
}
else if(strcmp(str,"END")==0){
continue;
}
else if(strcmp(str,"ENDOFINPUT")==0){
break;
}
else
{
for(i=0;i<strlen(str);i++)
{
if(str[i] > 'E' && str[i]<='Z')
str[i] = str[i]-5;
else if(str[i]>='A'&&str[i]<='E')
str[i] = str[i]+21;
}
puts(str);
}
}
return 0;
}
4202 子串
题目描述
现在有一些由英文字符组成的大小写敏感的字符串,你的任务是找到一个最长的字符串x,使得对于已经给出的字符串中的任意一个y,x或者是y的子串,或者x中的字符反序之后得到的新字符串是y的子串。
输入
输入的第一行是一个整数t (1 <= t <= 10),t表示测试数据的数目。对于每一组测试数据,第一行是一个整数n (1 <= n <= 100),表示已经给出n个字符串。接下来n行,每行给出一个长度在1和100之间的字符串。
输出
对于每一组测试数据,输出一行,给出题目中要求的字符串x的长度。
样例输入 复制
2
3
ABCD
BCDFF
BRCD
2
rose
orchid样例输出 复制
2
2
思路:
很恶心的暴力枚举。这道题就是枚举所有的子串和翻转串,再把所有的枚举情况一一判断一遍是否成立。
字符数组要随时清空,strstr函数要去了解一下,用于在一个字符串(主串)中查找第一次出现的另一个字符串(子串)的位置,找不到会返回NULL。
代码C语言:
#include<stdio.h>
#include<string.h>
char str[105][105];
int min(int a,int b){
return a < b ? a : b;
}
int max(int a,int b){
return a > b ? a : b;
}
void solve(){
int n;
scanf("%d",&n);
int minn = 100000;
int len = 0;
for(int i = 1;i <= n;i++){
scanf("%s",str[i]);
len = strlen(str[i]);
minn = min(minn,len);
}
char temp[100];
int len1 = strlen(str[1]);
int ans = 0;
int length = 0;
for(int j = 0;j < len;j++){
memset(temp,'\0',sizeof(temp));
for(int k = 1;k <= len;k++){
if(j + k > len1) continue;
strncpy(temp,str[1] + j,k);
length = strlen(temp);
int flag = 0;
char rev[105] = {'\0'};
for(int l = 0;l < length;l++){
rev[l] = temp[length - l - 1];
}
for(int i = 2;i <= n;i++){
if(strstr(str[i],temp)|| strstr(str[i],rev)){
}else{
flag = 1;
break;
}
}
if(!flag){
ans = max(length,ans);
}
}
}
printf("%d\n",ans);
}
int main(){
int t;
scanf("%d",&t);
while(t--) solve();
}4203 IBM减一
题目描述
你可能听说过Arthur C. Clarke的书“2001-太空奥德赛”,或者由Stanley Kubrick写的同名电影。书中描述的是一艘从地球飞往土星的太空船上发生的事情。长途飞行,船员都很疲劳,只有两个人是清醒的。飞船由智能电脑HAL控制的。但在飞行中,HAL操作变得越来越奇怪,甚至开始要杀死船上的船员。我们不告诉你故事的结局,你可以试着亲自去阅读。 电影上映后,大受欢迎。人们开始讨论“HAL”的名字真正的含义是什么。有人认为它可能是“启发式算法”的缩写。有人发现,如果把HAL中的每个字母都替换成字母表中其后的字母,就会得到“IBM”。 用这个方法也许能够找出更多的缩写词。请你编程帮忙找出这些单词。
输入
第1行为一个整数n,表示n个字符串。接下来的n行中,每行为一个不超过50大写字母的字符串。
输出
对输入文件中的每个字符串,先输出字符串的序号,如输出样例所示。最后输出变换后对应的字符串,即用字母表中后面的字母替换,其中‘Z’用‘A’替换。 每个测试数据之后,输出一个空行。
样例输入 复制
2
HAL
SWERC样例输出 复制
String #1
IBM
String #2
TXFSD
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
int n;
scanf("%d",&n);
for(int i = 1;i <= n;i++){
char str[1000];
scanf("%s",str);
int len = strlen(str);
for(int j = 0;j < len;j++){
str[j]++;
if(str[j] > 'Z') str[j] = 'A';
}
printf("String #%d\n",i);
printf("%s\n",str);
printf("\n");
}
}4204 W密码
题目描述
加密一条信息需要三个整数码, k1, k2 和 k3。字符[a-i] 组成一组, [j-r] 是第二组, 其它所有字符 ([s-z] 和下划线)组成第三组。 在信息中属于每组的字符将被循环地向左移动ki个位置。 每组中的字符只在自己组中的字符构成的串中移动。解密的过程就是每组中的字符在自己所在的组中循环地向右移动ki个位置。 例如对于信息 the_quick_brown_fox 以ki 分别为 2, 3 和 1进行加密。加密后变成 _icuo_bfnwhoq_kxert。下图显示了右旋解密的过程。
右旋解密示意图
观察在组[a-i]中的字符,我们发现{i,c,b,f,h,e}出现在信息中的位置为{2,3,7,8,11,17}。当k1=2右旋一次后, 上述位置中的字符变成{h,e,i,c,b,f}。下表显示了经过所有第一组字符旋转得到的中间字符串,然后是所有第二组,第三组旋转的中间字符串。在一组中变换字符将不影响其它组中字符的位置。
所有输入字符串中只包含小写字母和下划线( _ )。每个字符串的长度不超过80个字符。ki 是1-100之间的整数。
输入
输入包括一到多组数据。每个组前面一行包括三个整数 k1, k2 和 k3,后面是一行加密信息。输入的最后一行是由三个0组成的。
输出
对于每组加密数据,输出它加密前的字符串。
样例输入 复制
2 3 1
_icuo_bfnwhoq_kxert
1 1 1
bcalmkyzx
3 7 4
wcb_mxfep_dorul_eov_qtkrhe_ozany_dgtoh_u_eji
2 4 3
cjvdksaltbmu
0 0 0样例输出 复制
the_quick_brown_fox
abcklmxyz
the_quick_brown_fox_jumped_over_the_lazy_dog
ajsbktcludmv
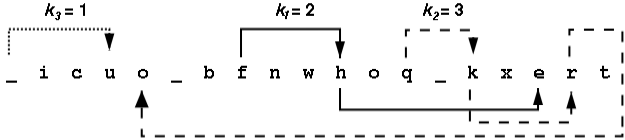

思路:
这道题就跟着去模拟,先分组存储,记得存储索引,不然之后不知道输出哪个组的值。
分组存储后,模拟移动,每一组向右移动k位。第三组的下划线记得要特判一下。
虽然模拟很复杂,但是分解起来也不难,每一组做的事情都是一样的。
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
int k1,k2,k3;
while(~scanf("%d %d %d",&k1,&k2,&k3)){
if(!k1 && !k2 && !k3) break;
char group1[2000] = {'\0'};
char group2[2000] = {'\0'};
char group3[2000] = {'\0'};
char str[2000] = {'\0'};
scanf("%s",str);
int len = strlen(str);
int a = 0;
int b = 0;
int c = 0;
int index[2000] = {0};
//分组读入
//index数组用来索引
for(int i = 0 ;i < len;i++){
if(str[i] >= 'a' && str[i] <= 'i'){
group1[a++] = str[i];
index[i] = 1;
}
if(str[i] >= 'j' && str[i] <= 'r'){
group2[b++] = str[i];
index[i] = 2;
}
if(str[i] >= 's' && str[i] <= 'z' || str[i] == '_'){
group3[c++] = str[i];
index[i] = 3;
}
}
//移动group1
for(int i = a - 1;i >= 0;i--){
group1[i + k1] = group1[i];
}
for(int i = a;i <= 200;i++){
if(group1[i] >= 'a' && group1[i] <= 'z'){
group1[i - a] = group1[i];
}else{
break;
}
}
group1[a] = '\0';
//移动group2
for(int i = b - 1;i >= 0;i--){
group2[i + k2] = group2[i];
}
for(int i = b;i <= 200;i++){
if(group2[i] >= 'a' && group2[i] <= 'z'){
group2[i - b] = group2[i];
}else{
break;
}
}
group2[b] = '\0';
//移动group3
for(int i = c - 1;i >= 0;i--){
group3[i + k3] = group3[i];
}
for(int i = c;i <= 200;i++){
if(group3[i] >= 'a' && group3[i] <= 'z' || group3[i] == '_'){
group3[i - c] = group3[i];
}else{
break;
}
}
group3[c] = '\0';
//开始按照index数组的索引输出
int index1 = 0;
int index2 = 0;
int index3 = 0;
for(int i = 0;i < len;i++){
//输出分组1
if(index[i] == 1){
printf("%c",group1[index1++]);
}
//输出分组2
if(index[i] == 2){
printf("%c",group2[index2++]);
}
//输出分组3
if(index[i] == 3){
printf("%c",group3[index3++]);
}
}
printf("\n");
}
}4205 字符长度编码
题目描述
你的任务是编程实现一个简单的字符长度编码方法。具体规则如下: 将任何由2~9个相同字符构成的序列用2个字符编码:第1个字符为数字2~9,表示序列长度,第2个字符为重复字符本身。超过9个字符的,先对前9个字符进行编码,然后再编码剩余的。 如果子序列中没有任何重复的字符,则用字符“1”开头,然后是子序列本身,最后再以字符“1”结束。若字符串中含有字符“1”,则用两个“1”替换。
输入
输入文件包含若干行,每行的字符都是大小写字母字符,数字字符,空格或标点符号,没有其他字符。
输出
对输入文件中的每行进行长度编码输出。
样例输入 复制
AAAAAABCCCC
12344样例输出 复制
6A1B14C
11123124
思路:
按照题目的思路去模拟,笔者的代码也不太好参考。
这边可以给读者一些小思路:我们要先能判断连续和非连续,比如用计数的方式。如果是连续片段,就正常处理,那如果遇到非连续片段呢?就到下一次遇到连续片段的时候处理(如果是结尾的非连续片段就特判)。
笔者代码比较难以理解,这道题推荐读者自行实现,核心思路就是去模拟。
代码C语言:
#include<stdio.h>
#include<string.h>
int main(){
char str[1000];
while(~scanf("%s",str)){
char temp[100] = {'\0'}; //临时数组用于存储非重复字符序列
int len = strlen(str);
int cnt1 = 1; //用于计数连续字符的数量
int cnt2 = 0; //用于计数非重复字符序列的长度
int i = 0, j = 0;
for(i = 0; i < len; i += cnt1){
memset(temp, '\0', sizeof(temp)); //清空临时数组
cnt1 = 1;
for(j = i + 1; j < len; j++){
if(str[j] == str[j - 1]){
cnt1++;
}else{
break;
}
}
// 如果只有一个字符,说明不重复,增加非重复字符序列长度
if(cnt1 == 1){
cnt2++;
}else{
//如果之前有非重复字符序列,则输出它们的编码
if(cnt2 != 0){
strncpy(temp, str + i - cnt2, cnt2); // 把非重复字符序列复制到临时数组
//处理【1%s1】的部分
printf("1");
int l = strlen(temp);
for(int i = 0; i < l; i++){
if(temp[i] != '1') printf("%c", temp[i]);
else printf("11");
}
printf("1");
cnt2 = 0; //重置非重复字符序列长度
memset(temp, '\0', sizeof(temp));
}
//输出连续字符
printf("%d%c", cnt1, str[j - 1]);
}
}
//处理字符串末尾的非重复字符序列
//处理【1%s1】的部分
strncpy(temp, str + i - cnt2, cnt2);
if(temp[0] != '\0'){
printf("1");
int l = strlen(temp);
for(int i = 0; i < l; i++){
if(temp[i] != '1') printf("%c", temp[i]);
else printf("11");
}
printf("1");
}
printf("\n");
}
}4206 LC显示器
题目描述
你的一个朋友刚买了一台新电脑,目前为止,他曾经使用过的最强大的电脑一直是一个袖珍计算器。他对新电脑非常失望,因为他喜欢那种计数器的LC显示器。因此你决定编程在你朋友的电脑上用LC显示器方式来显示数字。
输入
输入文件包含若干行,每一行中有两个整数s和n,(1 <= s <= 10,0 <= n <= 99999999)。N表示要显示的数字,s是它应显示的大小。最后一行为两个0,表示输入结束,这个不需要处理。
输出
以LC显示器的方式输出给定的数,用s个“-”水平线段,s个“|”垂直线段。每个数字刚好占s+2列,2s+3行。(请确保用空格填满所有数字之间的空白区域,包括最后一个数字),两个数字之间有一个空列。每组数字后输出一个空行。详见输入输出样例。
样例输入 复制
2 12345
3 67890
0 0样例输出 复制
— — —
| | | | | |
| | | | | |
— — — —
| | | | |
| | | | |
— — —
— — — — —
| | | | | | | |
| | | | | | | |
| | | | | | | |
— — —
| | | | | | | |
| | | | | | | |
| | | | | | | |
— — — —
思路:
这道题太难模拟了,不多解释,看代码。
打印的话就按行打印,然后依次遍历每一个数字。
代码C语言:
#include <stdio.h>
#include <string.h>
// 数字的LCD表示形式,0表示不打印,1表示水平线段,2表示垂直线段
int digits[10][7] = {
{1, 2, 2, 0, 2, 2, 1}, // 0
{0, 0, 2, 0, 0, 2, 0}, // 1
{1, 0, 2, 1, 2, 0, 1}, // 2
{1, 0, 2, 1, 0, 2, 1}, // 3
{0, 2, 2, 1, 0, 2, 0}, // 4
{1, 2, 0, 1, 0, 2, 1}, // 5
{1, 2, 0, 1, 2, 2, 1}, // 6
{1, 0, 2, 0, 0, 2, 0}, // 7
{1, 2, 2, 1, 2, 2, 1}, // 8
{1, 2, 2, 1, 0, 2, 1} // 9
};
// 打印一个数字的一行
void printLine(int digit, int line, int size) {
// 根据行号line确定打印哪一部分
int part = line / (size + 1); // 0, 1, 2
int pos = part * 3; // 数组中的位置: 0, 3, 6 对应上中下的水平线段
if (line % (size + 1) == 0) { // 打印水平线段
putchar(' '); // 左边的空白
for (int i = 0; i < size; i++) {
putchar(digits[digit][pos] ? '-' : ' ');
}
putchar(' '); // 右边的空白
} else { // 打印垂直线段
putchar(digits[digit][pos + 1] ? '|' : ' '); // 左边的垂直线段
for (int i = 0; i < size; i++) {
putchar(' '); // 中间的空白
}
putchar(digits[digit][pos + 2] ? '|' : ' '); // 右边的垂直线段
}
}
// 打印数字n的LCD表示
void printLCD(int size, char number[]) {
int length = strlen(number);
for (int line = 0; line < 2 * size + 3; line++) { // 总共2s+3行
for (int num = 0; num < length; num++) { // 遍历每个数字
int digit = number[num] - '0'; // 将字符转换为数字
printLine(digit, line, size); // 打印当前行
if (num < length - 1) {
putchar(' '); // 数字之间的空白列
}
}
putchar('\n'); // 每一行后换行
}
}
int main() {
int s;
char n[9];
while (scanf("%d %s", &s, n) == 2 && (s || strcmp(n, "0"))) {
printLCD(s, n);
printf("\n"); // 每组数字后输出一个空行
}
return 0;
}4207 英语到数字翻译
题目描述
给你一个或多个表示整数的英文单词,你的任务就是把这些英文单词表示的整数翻译成数字形式。数字的范围是从-999999999到+999999999。以下是可能出现的英文单词: negative,zero,one,two,three,four,five,six,seven,eight,nini,ten,eleven,twelve,thirteen,fourteen,fifteen,sixteen,seventeen,eighteen,nineteen,twenty,thirty,forty,fifty, sixty,seventy,eighty,ninety,hundred,thousand,millon
输入
输入包含多组测试数据。需要注意以下输入,负数前面用negative单词;当能用thousand表示时,就不用hundred来表示。例如,1500表示成one thousand five hundred,而不是fifteen hundred。
输出
输出翻译后的整数,占一行。
样例输入 复制
six
negative seven hundred twenty nine
one million one hundred one
eight hundred fourteen thousand twenty two样例输出 复制
6
-729
1000101
814022
思路:
按照题目就模拟,把英文转换成数字,然后逐个处理。没遇到乘数词之前就累加,遇到大的乘数词之后就翻倍,然后重新累加。
具体看代码~
代码C语言:
#include<stdio.h>
#include<string.h>
int wordToNumber(char word[]) {
if (strcmp(word, "zero") == 0) return 0;
if (strcmp(word, "one") == 0) return 1;
if (strcmp(word, "two") == 0) return 2;
if (strcmp(word, "three") == 0) return 3;
if (strcmp(word, "four") == 0) return 4;
if (strcmp(word, "five") == 0) return 5;
if (strcmp(word, "six") == 0) return 6;
if (strcmp(word, "seven") == 0) return 7;
if (strcmp(word, "eight") == 0) return 8;
if (strcmp(word, "nine") == 0) return 9;
if (strcmp(word, "ten") == 0) return 10;
if (strcmp(word, "eleven") == 0) return 11;
if (strcmp(word, "twelve") == 0) return 12;
if (strcmp(word, "thirteen") == 0) return 13;
if (strcmp(word, "fourteen") == 0) return 14;
if (strcmp(word, "fifteen") == 0) return 15;
if (strcmp(word, "sixteen") == 0) return 16;
if (strcmp(word, "seventeen") == 0) return 17;
if (strcmp(word, "eighteen") == 0) return 18;
if (strcmp(word, "nineteen") == 0) return 19;
if (strcmp(word, "twenty") == 0) return 20;
if (strcmp(word, "thirty") == 0) return 30;
if (strcmp(word, "forty") == 0) return 40;
if (strcmp(word, "fifty") == 0) return 50;
if (strcmp(word, "sixty") == 0) return 60;
if (strcmp(word, "seventy") == 0) return 70;
if (strcmp(word, "eighty") == 0) return 80;
if (strcmp(word, "ninety") == 0) return 90;
if (strcmp(word, "hundred") == 0) return 100;
if (strcmp(word, "thousand") == 0) return 1000;
if (strcmp(word, "million") == 0) return 1000000;
if (strcmp(word, "negative") == 0) return -1;
return -2;
}
int main() {
char str[1000] = {'\0'};
while (fgets(str, sizeof(str), stdin)) {
//处理换行符
int len = strlen(str);
if (str[len - 1] == '\n') {
str[len - 1] = '\0';
len--;
}
int num = 0;
int sum = 0;
int tempValue = 0;
int multiplier = 1;
int negative = 0;//判断正负
char temp[100] = {'\0'};
int last = 0;
for (int i = 0; i <= len; i++) {
if (str[i] == ' ' || str[i] == '\0') {
int wordLength = i - last;
strncpy(temp, str + last, wordLength);
temp[wordLength] = '\0';
num = wordToNumber(temp);//获取数字
//开始处理
if (num == -1) { //正负
negative = 1;
} else if (num == 100 || num == 1000 || num == 1000000) {//遇到乘数词开始翻倍
if (tempValue == 0) tempValue = 1;
tempValue *= num;
if (num > 100) {
//num == 100不能加,防止什么one hundred twenty three thousand的情况
//因为thousand和million前面是可以有hundred的
sum += tempValue;//加到sum里,重新累加,为大的乘数词做准备
tempValue = 0;
}
} else if (num >= 0) {//正常加上
tempValue += num;
} else {
}
last = i + 1;
}
}
sum += tempValue;
if (negative) {
sum = -sum;
}
printf("%d\n", sum);
}
return 0;
}4208 多项式表示
题目描述
给定一个多项式,其幂从8到0,要求删除多项式中没用的字符,使之变成可读格式。例如,给定的系数为0、0、0、1、22、-333、0、1和-1,你应该输出:x5+22x4-333x^3+x-1。 转换多项式时需要遵守以下规则: (1)按幂的次数递减顺序。 (2)指数用“^”来表示。 (3)常数项仅用常数来表示。 (4)只有非0系数项才表示。如果所有项的系数全为0,才会输出常数项0。 (5)只有在“+”和“-”操作符的左右两边才会各有一个空格。 (6)第1项系数为正,则不需要正号;如果第1项的系数为负数,则要有“-”符号,如:-7x^2+30x+66。 (7)除了第1项外,系数为负数的项前的负号应该表示为减,也就是说,不能输出“x^2 + – 3x”,而应输出“x^2-3x”。 (8)常数1和-1只能出现在常数项,也就是说,不能输出“-1x3+1x2+3x1”,而应该输出“-x3+x^2+3x-1”。
输入
输入文件中包含若干个测试数据,每个测试数据占一行,为多项式的9个系数,用空格隔开,每个系数的绝对值不超过1000。
输出
对输入文件每个测试数据所给出的9个系数,输出一行,为对应的多项式。
样例输入 复制
0 0 0 1 22 -333 0 1 -1
0 0 0 0 0 0 -55 5 0样例输出 复制
x^5 + 22x^4 – 333x^3 + x – 1
-55x^2 + 5x
思路:
代码很好理解,思路也很好懂。我们从后往前看一遍,判断是否是第一项,第一项的前面不输出符号,其余都输出符号,然后负号也做一下判断。然后看是不是第一项或者第零项,如果不是第零项的话都有x,如果不是第零项和第一项的话都有指数标志。
代码C语言:
#include <stdio.h>
int main() {
int a[9];
//先读入
while (~scanf("%d %d %d %d %d %d %d %d %d",&a[8],&a[7],&a[6],&a[5],&a[4],&a[3],&a[2],&a[1],&a[0]) == 9) {
int first = 1;
for (int i = 8;i >= 0;i--) {
// 跳过系数为0的项
if (a[i] == 0) continue;
// 对于第一个非零项,不输出加号
if (first) {
first = 0;
// 如果系数为负数,输出负号
if (a[i] < 0) printf("-");
} else {
// 对于后续项,根据正负输出加号或减号
printf(" %c ", (a[i] > 0) ? '+' : '-');
}
// 输出系数(绝对值),除非系数为1或-1且非常数项
if (abs(a[i]) != 1 || i == 0) printf("%d", abs(a[i]));
// 输出x及其次幂
if (i > 0) printf("x");
if (i > 1) printf("^%d", i);
}
// 如果所有系数都是0,输出0
if (first) printf("0");
printf("\n");
}
return 0;
}4209 字符串的幂
题目描述
给定两个字符串a和b,定义a * b为两个字符串的联接。例如,a=“abc”,b=“def”,则a * b=“abcdef”。若将字符串的联接看作乘法,则字符串的非负整数次幂可这样定义:a ^ 0=“”(空串),a ^ (n+1)=a * (a ^ n)。
输入
每组测试数据占一行,为一个字符串s,s中的字符都是可显示的。s的长度至少为1,最多不超过1000000个字符。字符“.”,表示输入结束。
输出
对每个字符串s,输出最大整数n,满足:s=a ^ n,a为某个字符串。
样例输入 复制
abcd
aaaa
ababab样例输出 复制
1
4
3
思路:
这道题的思路就是去找有没有周期的存在。如果存在周期,就把字符串长度除以周期长度,就能输出幂次了。
代码C语言:
#include <stdio.h>
#include <string.h>
int find(char s[]) {
int len = strlen(s);
char ss[2000002]; //分配空间
strcpy(ss,s);
strcat(ss,s); //创建s + s
int i;
for (i = 1;i <= len;i++) {
if (strncmp(ss + i,s,len) == 0) {
break;
}
}
if(i > len){
return 1; //没有周期
}else{
return len / i; //有周期
}
}
int main() {
char s[1000001];
while (~scanf("%s", s)) {
if (strcmp(s,".") == 0) break;
printf("%d\n", find(s));
}
return 0;
}4210 回文
题目描述
一个规则的回文是一串由字符或数字组成的字符串,从前往后读与从后往前读完全一样。例如,字符串“ABCDEDCBA”就是个回文字符串,从左到右和从右到左都是一样的。 所谓镜像字符串,就是将字符串中的每个字符用对应的相反字符(如果存在相反字符)替换后,得到的新字符串从后往前读,跟原来的字符串一样。例如,3AIAE就是一个镜像字符串,因为A和I是它们本身的相反字符,并且3和E互为相反字符。字符串3AIAE中,各字符转换成其相反字符后,变成EAIA3,这个字符串从后往前读,就是原来的字符串。 镜像回文就是同时满足回文字符串和镜像字符串条件的字符串。例如,ATOYOTA就是一个镜像回文,因为这个字符从后往前读和原来的一样,替换成相反字符后,得到ATOYOTA,从后往前读也和原来的一样。
注意:数字0和字符O被认为是同一个字符,因此只有字符O才是有效的字符。
输入
输入文件包括多个字符串,每行一个,每个字符串包含1~20个有效字符,不会包含无效字符。输入数据一直到文件尾。
输出
对输入的每个字符串,在第1列开始输出字符串本身,接着输出以下字符串中的一个: “ — is not a palindrome.” 既不是回文,也不是镜像字符串 “ — is a regular palindrome.”是回文,但不是镜像字符串 “ — is a mirrored string.”不是回文,但是镜像字符串 “ — is a mirrored palindrome.”既是回文也是镜像字符串 注意:请按照输出输出样例空格和字符“-”,每个输出后有一个空行。
样例输入 复制
NOTAPALINDROME
ISAPALINILAPASI
2A3MEAS
ATOYOTA样例输出 复制
NOTAPALINDROME — is not a palindrome.
ISAPALINILAPASI — is a regular palindrome.
2A3MEAS — is a mirrored string.
ATOYOTA — is a mirrored palindrome.
思路:
这道题很暴力,就是1、判断是否是回文,2、判断是否是镜像。
判断也很容易,回文的判断大家都会。镜像的判断就是要去打个表比较麻烦以外,也很容易得到镜像字符串,然后判断一下就行。
代码C语言:
#include <stdio.h>
#include <string.h>
int main(){
char str[1000];
while(~scanf("%s",str)){
int flag1 = 1,flag2 = 1;
char str2[1000] = {'\0'};
int len = strlen(str);
int i;
for(i = 0;i <= len/2;i++){
if(str[i]!=str[len - i - 1]){
flag1 = 0;
}
}
int j = 0;
for(i = 0;i < len;i++){
if(str[i]=='A'||str[i]=='H'||str[i]=='I'||str[i]=='M'||str[i]=='O'||str[i]=='T'||str[i]=='U'||str[i]=='V'||str[i]=='W'||str[i]=='X'||str[i]=='Y'||str[i]=='8')
str2[j++] = str[i];
if(str[i]=='E')
str2[j++] = '3';
if(str[i]=='J')
str2[j++] = 'L';
if(str[i]=='L')
str2[j++] = 'J';
if(str[i]=='S')
str2[j++] = '2';
if(str[i]=='Z')
str2[j++] = '5';
if(str[i]=='2')
str2[j++] = 'S';
if(str[i]=='3')
str2[j++] = 'E';
if(str[i]=='5')
str2[j++] = 'Z';
}
for(i = 0;i < len;i++){
if(str2[i] != str[len - i - 1]){
flag2 = 0;
}
}
if(flag1==1&&flag2==1){
printf("%s -- is a mirrored palindrome.\n",str);
}
if(flag1==0&&flag2==0){
printf("%s -- is not a palindrome.\n",str);
}
if(flag1==1&&flag2==0){
printf("%s -- is a regular palindrome.\n",str);
}
if(flag1==0&&flag2==1){
printf("%s -- is a mirrored string.\n",str);
}
printf("\n");
}
return 0;
} 4211 填词游戏
题目描述
Alex喜欢填词游戏。填词游戏是一个非常简单的游戏。填词游戏包括一个N * M大小的矩形方格盘和P个单词。然后需要把每个方格中填上一个字母使得每个单词都能在方格盘上被找到。每个单词都能被找到要满足下面的条件: 每个方格都不能同时属于超过一个的单词。一个长为k的单词一定要占据k个方格。单词在方格盘中出现的方向只能是竖直的或者水平的(可以由竖直转向水平,反之亦然)。 你的任务是首先在方格盘上找到所有的单词,当然在棋盘上可能有些方格没有被单词占据。然后把这些没有用的方格找出来,把这些方格上的字母按照字典序组成一个“神秘单词”。 如果你还不了解规则,我们可以用一个例子来说明,比如在图 中寻找单词BEG和GEE。
输入
输入的第一行包括三个整数N,M和P (2 <= M, N <= 10, 0 <= P<=100)。接下来的N行,每行包括M个字符来表示方格盘。接下来P行给出需要在方格盘中找到的单词。 输入保证填词游戏至少有一组答案。输入中给出的字母都是大写字母。
输出
输出“神秘单词”,注意“神秘单词”中的字母要按照字典序给出。
样例输入 复制
3 3 2
EBG
GEE
EGE
BEG
GEE样例输出 复制
EEG
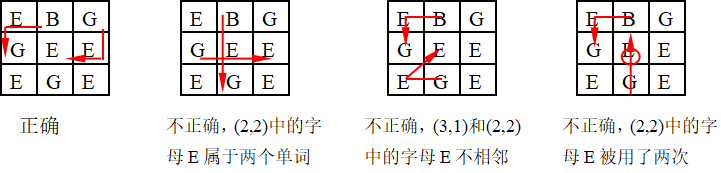
思路:
这道题没那么难,就是去重。前面先计数,看看表格里每个字母有多少个,然后把要输出的单词的字母给去掉,剩下的就是我们要的了。
代码C语言:
#include<stdio.h>
#include<string.h>
char mx[100][100];
int vis[1000];
int main(){
int n,m,p;
while(~scanf("%d %d %d",&n,&m,&p)){
getchar();
memset(vis,0,sizeof(vis));
char temp[100] = {'\0'};
for(int i = 1;i <= n;i++){
scanf("%s",temp);
for(int j = 0;j < m;j++){
vis[temp[j] - 'A']++;
}
}
for(int i = 1;i <= p;i++){
scanf("%s",temp);
int len = strlen(temp);
for(int j = 0;j < len;j++){
vis[temp[j] - 'A']--;
}
}
for(int i = 0;i < 26;i++){
while(vis[i] > 0){
printf("%c",'A' + i);
vis[i]--;
}
}
}
}4212 字符串相等
题目描述
判断两个由大小写字母和空格组成的字符串在忽略大小写和压缩掉空格后是否相等。
输入
第1行是测试数据的组数n,每组测试数据占2行,第1行是第一个字符串s1,第2行是第二个字符串s2。 每组测试数据之间有一个空行,每行数据不超过100个字符(注意字符串的长度可能为0)。
输出
n行,相等则输出YES,否则输出NO。
样例输入 复制
3
a A bb BB ccc CCC
Aa BBbb CCCccc
a dfadf fasdf
adasddfsfsaf样例输出 复制
YES
YES
NO
代码C语言:
#include<stdio.h>
#include<string.h>
#include<ctype.h>
#define MAXN 100
int solve(char s1[],char s2[]){
int i = 0, j = 0;
while(s1[i] || s2[j]){
//跳过空格
while(s1[i] && s1[i] == ' ') i++;
while(s2[j] && s2[j] == ' ') j++;
//转换成小写比较
if(tolower((char)s1[i]) != tolower((char)s2[j])){
return 0;
}
if(s1[i]) i++;
if(s2[j]) j++;
}
return 1;
}
int main() {
int n;
scanf("%d", &n);
getchar();
for (int i = 0; i < n; ++i) {
char s1[MAXN + 1], s2[MAXN + 1];
fgets(s1, MAXN + 1, stdin);
fgets(s2, MAXN + 1, stdin);
//替换换行符
s1[strcspn(s1,"\n")] = '\0';
s2[strcspn(s2,"\n")] = '\0';
if (solve(s1, s2)) {
printf("YES\n");
} else {
printf("NO\n");
}
if (i != n - 1) {
getchar();
}
}
return 0;
}4213 置换加密算法
题目描述
置换加密算法是最简单的加密算法,就是将一个字母表中的字符置换成另一个字母表中的字符,这种密方法,已经存在2000多年的历史了。
输入
第1行是原文字母表,第2行是替换用的字母表。剩下的便是原文。
输出
输出的第1行是替换用的字母表,第2行是原文字母表。接下来是将替换后得到的密文字符串。 注意:每行最多64个字符(包括结束符)。所有的字符都在原文字母表中。
样例输入 复制
abcdefghijklmnopqrstuvwxyz
zyxwvutsrqponmlkjihgfedcba
Shar’s Birthday:
The birthday is October 6th, but the party will be Saturday,
October 5. It’s my 24th birthday and the first one in some
years for which I’ve been employed. Plus, I have new clothes.
So I have cause to celebrate. More importantly, though,
we’ve cleaned the house! The address is 506-D Albert Street.
Extra enticement for CS geeks: there are several systems in
the house, and the party is conveniently scheduled for 3 hours
after the second CSC programming contest ends (not to mention,
within easy walking distance)!样例输出 复制
zyxwvutsrqponmlkjihgfedcba
abcdefghijklmnopqrstuvwxyz
Sszi’h Brigswzb:
Tsv yrigswzb rh Oxglyvi 6gs, yfg gsv kzigb droo yv Szgfiwzb,
Oxglyvi 5. Ig’h nb 24gs yrigswzb zmw gsv urihg lmv rm hlnv
bvzih uli dsrxs I’ev yvvm vnkolbvw. Pofh, I szev mvd xolgsvh.
Sl I szev xzfhv gl xvovyizgv. Mliv rnkligzmgob, gslfts,
dv’ev xovzmvw gsv slfhv! Tsv zwwivhh rh 506-D Aoyvig Sgivvg.
Ecgiz vmgrxvnvmg uli CS tvvph: gsviv ziv hvevizo hbhgvnh rm
gsv slfhv, zmw gsv kzigb rh xlmevmrvmgob hxsvwfovw uli 3 slfih
zugvi gsv hvxlmw CSC kiltiznnrmt xlmgvhg vmwh (mlg gl nvmgrlm,
drgsrm vzhb dzoprmt wrhgzmxv)!
思路:
思路就是搞一个映射,没什么好说的。但是笔者格式错误了很久,最后发现读入字母表的时候必须要用fgets,防止空格等特殊情况。
代码C语言:
#include <stdio.h>
#include <string.h>
#include <ctype.h>
char a[1000];
char b[1000];
int find(char x){
int len = strlen(a);
for(int i = 0; i < len; i++){
if(a[i] == x){
return i;
}
}
return -1;
}
int main(){
char str[1000] = {'\0'};
fgets(a,sizeof(a),stdin);
fgets(b,sizeof(b),stdin);
printf("%s",b);
printf("%s",a);
while(fgets(str,sizeof(str),stdin)){//换行符也会被读入
int len = strlen(str);
for(int i = 0; i < len; i++){
//不是字母就正常输出
if(find(str[i]) == -1){
printf("%c",str[i]);
continue;
}
//先找到这个字母是原字母表中的第几个
int index = find(str[i]);
printf("%c",b[index]);
}
memset(str,'\0',sizeof(str));
}
}4301 词组缩写
题目描述
定义:一个词组中每个单词的首字母的大写组合称为该词组的缩写。
比如,C语言里常用的EOF就是end of file的缩写。输入
输入的第一行是一个整数T,表示一共有T组测试数据。
接下来有T行,每组测试数据占一行,每行有一个词组,每个词组由一个或多个单词组成;每组的单词个数不超过10个,每个单词有一个或多个大写或小写字母组成;
单词长度不超过10,由一个或多个空格分隔这些单词。输出
请为每组测试数据输出规定的缩写,每组输出占一行。
样例输入 复制
1 end of file样例输出 复制
EOF
思路:
正常去模拟就好,空格后面的第一个英文字母转换成大写,然后对于整个文本的第一个英文字母也要转成大写,简单处理一下就行【笔者的写法有点丑,读者自行处理】
代码C++:
#include<bits/stdc++.h>
using namespace std;
int t;
void solve(){
string s;
getline(cin,s);
int len = s.size();
int flag = 0;//flag 来给第一个输出的元素打标记
for(int i = 0;i < len;i++){
char temp;
if(flag == 0 && s[i] != ' ') flag = 1;
//大小写判断
if(flag == 1 && (s[i] >= 'a' && s[i] <= 'z')){
temp = s[i] - 32;
cout << temp;
flag = 2;
}
if(flag == 1 && (s[i] >= 'A' && s[i] <= 'Z')){
temp = s[i];
cout << temp;
flag = 2;
}
if(s[i] == ' ' && (s[i + 1] >= 'a' && s[i + 1] <= 'z')){
temp = s[i + 1] - 32;
cout << temp;
}
if(s[i] == ' ' && (s[i + 1] >= 'A' && s[i + 1] <= 'Z')){
temp = s[i + 1];
cout << temp;
}
}
cout << "\n";
}
int main(){
cin >> t;
cin.get();
while(t--) solve();
}4302 墓碑上的字符
题目描述
考古学家发现了一座千年古墓,墓碑上有神秘的字符。经过仔细研究,发现原来这是开启古墓入口的方法。
墓碑上有2行字符串,其中第一个串的长度为偶数,现在要求把第2个串插入到第一个串的正中央,如此便能开启墓碑进入墓中。输入
输入数据首先给出一个整数n,表示测试数据的组数。
然后是n组数据,每组数据2行,每行一个字符串,长度大于0,小于50,并且第一个串的长度必为偶数。输出
请为每组数据输出一个能开启古墓的字符串,每组输出占一行。
样例输入 复制
2 CSJI BI AB CMCLU样例输出 复制
CSBIJI ACMCLUB
思路:
可以去选择模拟,但是无论是c++还是c都已经有了很多字符串函数~直接用现成的就好。
代码C++:
#include<bits/stdc++.h>
using namespace std;
void solve(){
string s1,s2;
cin >> s1 >> s2;
int index = (s1.size()) / 2;
s1.insert(index,s2);
cout << s1 << "\n";
}
int main(){
int n;
cin >> n;
while(n--) solve();
}总结
- 真是酣畅淋漓的字符串模拟。整体难度中等,部分题目中等偏上,实在是太难模拟了。
- 写字符串模拟比较费时间,读者要有耐心。
- 需要了解大量字符串函数,可以节省很多时间,比如strstr、strncpy,strncmp等等。
- 字符串处理要注意边界还有’\0’,注意换行等等。